About Me
Hello! I’m Sapana, a scientist at Amazon AGI, focused on reinforcement learning (RL) post-training. I build the RL systems that turn small open-source models into specialized agents and models—often matching much larger general-purpose ones. My PhD was on online learning, RL, and RLHF, with a focus on safe and adaptive sequential decision making—algorithms that satisfy unknown safety constraints and stay reliable under distribution shift. I received my doctorate from Texas A&M University (TAMU) working with Dr. Dileep Kalathil.
News
- [Aug 2026] Presenting a hands-on tutorial at KDD 2026: Multi-Turn RL for LLMs: From Theory to Practice with Amazon SageMaker AI!
- [Jun 2026] Multi-Turn RL (MTRL) launched on Amazon SageMaker AI!
- [Jan 2026] VeriCoT accepted to ICLR!
- [Jan 2026] New paper on kernel code optimization out on arxiv!
- [Dec 2025] Serverless open source model Reinforcement Fine-Tuning (RFT) launched on AWS SageMaker!
Multi-Turn Reinforcement Learning in Amazon SageMaker AI
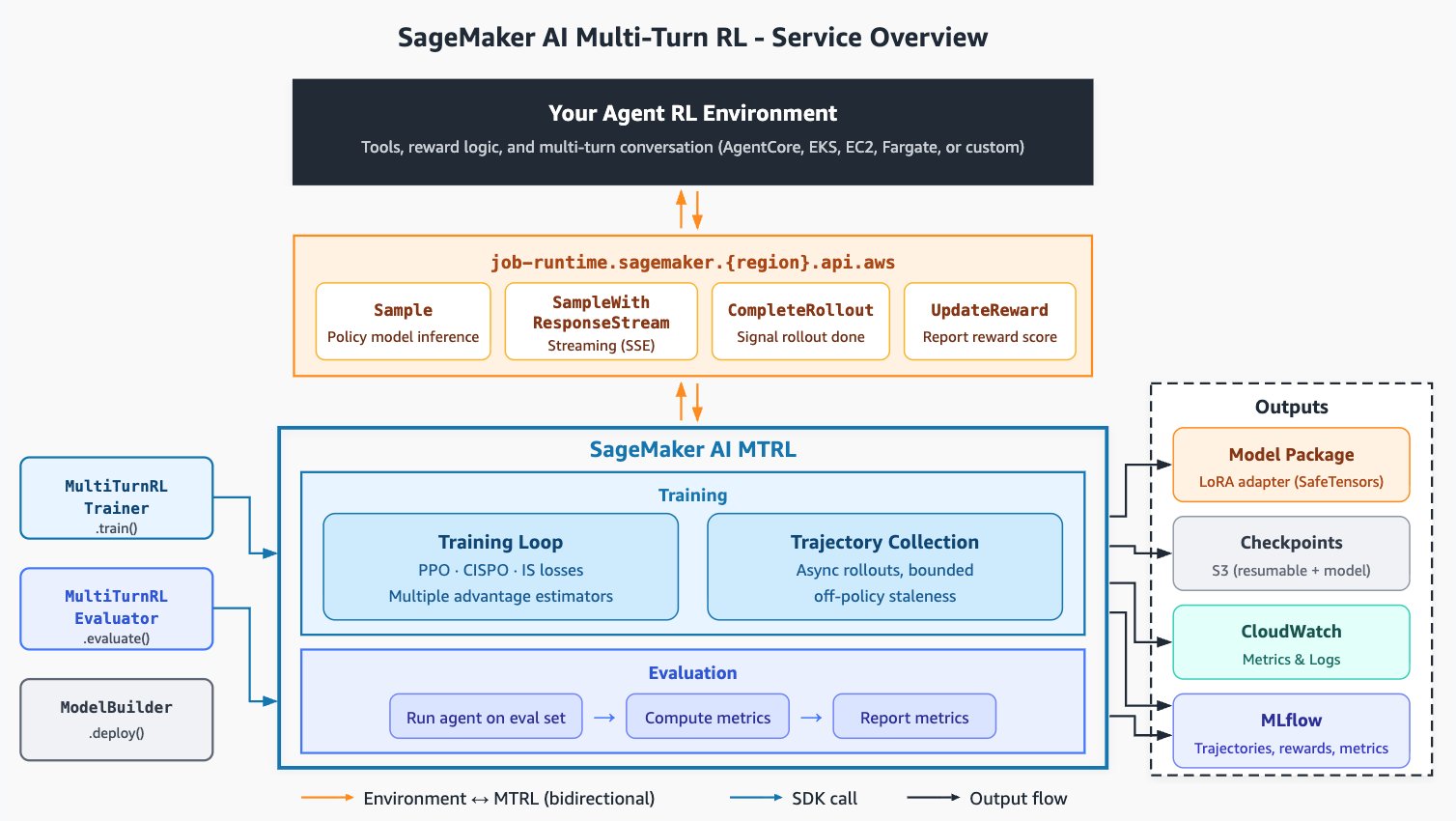
I’m the science tech lead for SageMaker AI Multi-Turn RL (MTRL), a fully serverless model customization service that runs the entire agentic RL loop—rollout orchestration, trajectory collection, training, checkpoints, and evaluation—on open-source models like Qwen, GPT-OSS, and Gemma, with no infrastructure setup required. To learn more, see this best-practices guide using the Amazon Science SOP (Standard Operating Procedure)-Bench benchmark as a running example: Best practices for Multi-Turn RL in Amazon SageMaker AI.
Reinforcement Fine-Tuning on Amazon Bedrock and SageMaker AI
Before MTRL, I was a core contributor to Amazon Bedrock and SageMaker AI Reinforcement Fine-Tuning (RFT), the single-turn post-training service for open-source models (launched December 2025). RFT customizes models like Qwen, Meta’s Llama, DeepSeek, OpenAI’s gpt-oss—from reward signals instead of large labeled datasets, via RLAIF, RLVR, SFT, and DPO, with no infrastructure to manage. I co-authored the best-practices guide: Reinforcement fine-tuning on Amazon Bedrock: Best practices.
Selected Research Work
- MaxCode (arXiv 2026) — max-reward RL framework for LLM-driven code optimization on CUDA (KernelBench) and C++ (PIE). +20.3% relative improvement in absolute speedup value and +10.1% in relative speedup ranking over baselines.
- RA-RLHF (NeurIPS 2024) — CVaR-based PPO objective that suppresses rare-but-significant toxic generations during RLHF.
- AgentOccam (ICLR 2025) — showed that aligning a web agent’s observation and action space to LLM pretraining beats elaborate prompting, search, and multi-agent scaffolds. +9.8 pts over prior SOTA and +26.6 pts (+161%) over plain web agents on WebArena, without in-context examples or search.
Full publication list: sapanachaudhary.github.io/publications.
Aside from work, I like to hike, cook, paint, and photograph.